Enjeux et Défis de
l’IA
L’Intelligence Artificielle (IA) est partout dans nos téléphones, nos télés, nos réfrigérateurs, mais qu’en est-il du domaine pharmaceutique ? Les enjeux et les bénéfices sont importants, mais quels sont les défis imposés par la réglementation et les risques liés au produit et à la santé du patient ? Dans cet article, nous reviendrons sur l’IA et notamment son impact sur la validation des systèmes informatisés.
Mais qu’est-ce que l’IA ?
L’IA est une interconnexion de réseaux de neurones dont le but est d’imiter le fonctionnement du cerveau humain. Un neurone artificiel est une fonction complexe permettant d’analyser des données complexes, de les pondérer afin de fournir une réponse la plus probable.
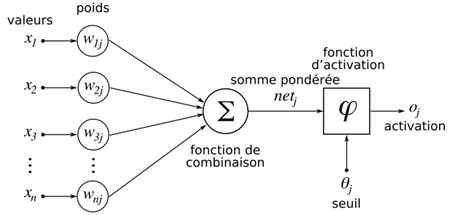
Suivant l’organisation des neurones dans le réseau, l’IA sera plus ou moins pertinente pour la reconnaissance d’images, la génération de texte, …
Programme et l’IA ?
Une application est le résultat de la programmation d’un développeur suivant un algorithme et afin de répondre à un comportement souhaité décrit par les User Requirements Specification (URS) et ce programme fournira toujours la même réponse pour une même entrée donnée. On parle alors de réponse déterministe.
Une IA est quant à elle le résultat de l’entraînement d’un modèle avec des données d’entrée et de sortie. Il est ainsi possible de lui faire apprendre à reconnaitre un chat en lui montrant des photos de chat (données d’entrée) identifiées comme étant un chat (donnée de sortie). Le modèle entrainé sera alors capable de reconnaitre un chat avec plus ou moins de chances en fonction de la quantité de données qu’il aura apprise. On parle alors de réponse probabiliste.
On devine les possibilités et les limites d’une IA par rapport à un programme classique. L’IA sera capable de traiter un plus large spectre de données mais avec plus ou moins de résultat suivant l’apprentissage
Domaine d'application de l’IA ?
En reprenant la définition d’une IA et en réfléchissant à sa différence avec une application, on
devine que l’IA peut être utilisée sur l’ensemble du cycle de vie du médicament dans le cas où le
nombre de données d’entrée à traiter est trop important pour une application classique dont
l’algorithme a été conçu pour traiter un nombre limité de données bien spécifiques.
Elle pourrait être utiliser :
-
Pour recruter des patients en amont des essais cliniques,
-
Pour optimiser un processus de production,
-
Réaliser de l’inspection visuelle à la sortie d’une ligne de production
Les données - un enjeu pour l’IA
Ces 3 cas d’utilisation de l’IA permettent de nous donner une idée de l’importance des données et de leur traitement avant qu’elles ne servent à entrainer le modèle d’IA.
En effet, si des données comportent des informations personnelles il est nécessaire alors de les anonymiser afin de respecter le RGPD. Il est aussi important pour l’entreprise d’avoir digitalisé ses processus afin d’avoir une quantité suffisante de données pour entrainer le modèle d’IA. Ces données doivent également être intègres, de qualité mais aussi triées.
La réglementation et l’IA
Sur ce point, l’arsenal réglementaire existant (Annex 11 pour l’Europe ou la Part 11 pour les USA) nous permet de valider dans l’état une intelligence artificielle. Les principes suivants décrits dans ces 2 textes réglementaires suffisent :
-
L’automatisation d’un processus ne doit pas apporter de risque supplémentaire
-
Une approche risque est nécessaire afin de prouver que le système mis en place prend en compte la sûreté du patient, l’intégrité des données et la qualité du produit.
De plus l’Europe a publié l’AI Act en 2024. Une approche « Critical Thinking » y est définie et 4 niveaux de risques sont décrits pour l’IA en prenant en compte la santé du patient, la transparence concernant l’apprentissage et la validation du modèle et la qualité des données.
l’IA et validation – un défi
La FDA a publié en 2019 une guidance « Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML) – Based Software as a Medical Device (SaMD) § Discussion Paper and Request for Feedback” proposant une première approche pour la validation d’une IA. L’ISPE dans la 2nd édition du GAMP®5 propose également une approche similaire.
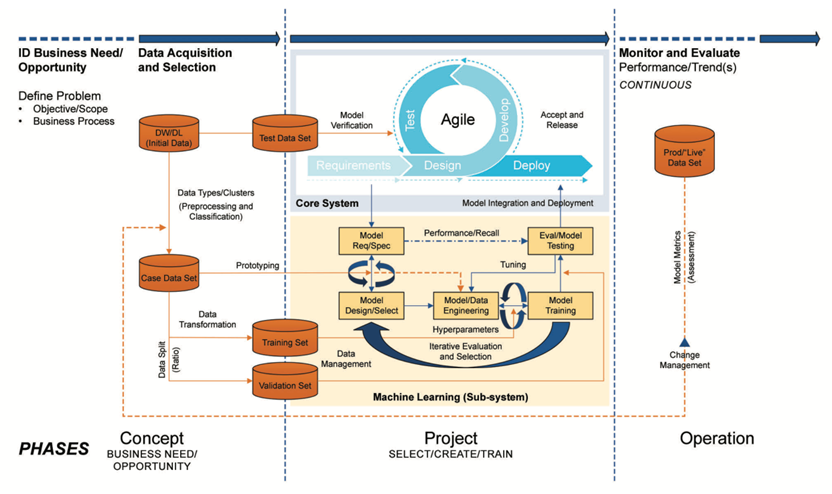
Le grand défi de la validation d’une IA est dans un premier temps de valider un modèle entrainé sur des données non biaisées et dans un second temps de maintenir son état valider alors qu’une IA est censée auto-apprendre avec les données live.
Pour cela, les grandes idées de l’approche de validation sont :
-
Un traitement et une validation des données incluant leur nettoyage, transformation et préparation. Le but étant d’avoir des données intègres et de qualité représentant le mieux possible les processus, il faut éviter les biais qui orienterait l’apprentissage dans une mauvaise direction.
-
Il faut séparer les jeux de données en données de training, validation et test. Les données de training sont utilisées pour entrainer le modèle et réaliser le fine tuning des paramètres. Les données de validation sont là pour tester le modèle lors de ces phases itératives d’apprentissage.
Les données de test doivent être indépendantes de cette phase itérative afin de tester le modèle final dans son environnement intégré. -
Une phase de design va permettre de définir le modèle plus adapté avant l’entrainement et de le spécifier en toute transparence.
-
Une fois le modèle en production, sa performance sera suivie au travers d’indicateur. Au fur et à mesure que les données de production seront disponibles, le modèle pourra être enrichi et tester en fonction de la mesure des indicateurs. Cette phase d’enrichissement doit se faire au travers de change control afin de contrôler l’entrainement et l’évolution du modèle avec les données de production.
S’il ne fallait retenir que 3 points essentiels pour la mise en place d’une IA dans un
environnement pharmaceutique réglementé, ce serait :
• Il faut au préalable avoir à disposition un jeu de données en quantité et qualité
suffisante
afin de représenter au mieux le processus.
• Ne pas tester le modèle avec le même jeu de données d’apprentissage.
• Limiter et contrôler l’apprentissage du modèle une fois que celui-ci est en production
afin de
maintenir l’état validé de l’IA.